Theoretical Paper
- Computer Organization
- Data Structure
- Digital Electronics
- Object Oriented Programming
- Discrete Mathematics
- Graph Theory
- Operating Systems
- Software Engineering
- Computer Graphics
- Database Management System
- Operation Research
- Computer Networking
- Image Processing
- Internet Technologies
- Micro Processor
- E-Commerce & ERP
Practical Paper
Industrial Training

Relational Algebra Part 1
Relational Algebra and Relational Calculus
Many different DMLs can be designed to express database manipulations. Different DMLs will probably differ in syntax, but more importantly they can differ in the basic operations provided. For those familiar with programming, these differences are not unlike that found in different programming languages. There, the basic constructs provided can greatly differ in syntax and in their underlying approach to specifying computations. The latter can be very contrasting indeed - look at, for example, the differences between procedural (eg. C) and declarative (eg. Prolog) approaches to specifying computations.
Relational Algebra and Relational Calculus are two approaches to specifying manipulations on relational databases. The distinction between them is somewhat analagous to that between procedural and declarative programming. Thus, before looking at the details of these approaches, it is instructive to briefly digress and look at procedural and declarative programming a little more closely. We will then try to put into context how the algebra and calculus help in the design and implementation of DMLs.
Briefly, the procedural approach specifies a computation to be performed as explicit sequences of operations. The operations themselves are built from a basic set of primitive operations and structuring/control primitives that build higher level operations. An operation can determine the flow of control (ie. determines the next operation to be executed) and/or cause data to be transformed. Thus programming in the procedural style involves working out the operations and their appropriate order of execution to effect the desired transformation(s) on input data.
The declarative approach, in contrast, would specify the same computation as a description of the logical relationship between input and output data. These relationships are typically expressed as a set of truth-valued sentences about data objects. Neither operations nor their sequences are made explicit by the programmer. Operations are instead implicit in the predetermined set of rules of inference used to derive new sentences from those given (or derived earlier).
In other words, if you used a procedural programming language, you must specify how input is to be transformed to desired outputs using the basic operations available in the language. However, if you used a declarative language, you must instead describe what relationships must be satisfied between inputs and outputs, but essentially say nothing about how a given input is to be transformed to the desired output (it is for the system to determine how, typically by some systematic application of inference rules).
Amidst such differences, users are right to raise some basic concerns. Are these differences superficial? Or do they mean that there can be computations specifiable in one but not in the other? If the latter were the case, programmers must avoid choosing languages that simply cannot express some desired computation (assuming we know exactly the limitations of each and every programming language)! Fortunately for programmers, this is not the case. It is a well-known result that every general-purpose programming language (whether procedural or declarative) is equivalent to every other. That is, if something is computable at all, it can be specified in any of these languages. Such equivalence is established by reference to a fundamental model of computation that underlies the notion of computability.
Now what can we say about the different (existing and future) database languages? Can two different languages be said to be equivalent in some sense? To answer this question we must first ask whether, in relational databases, there is a fundamental model of database manipulation? The answer is yes - Relational Calculus defines that model!
Recollect that the Universal Turing Machine (model of computation) is accepted as defining the class of all computable functions. Every programming language shown to be equivalent to it is therefore equivalent with every other.
Let us first state a fundamental definition:
A language that can define any relation definable in relational calculus is relationally complete.
This definition provides a benchmark by which any existing (and future) language may be judged as to its power of expression. Different languages may thus be equivalent in the sense of being relationally complete.
Note however, that relational completeness is not the same as computational completeness, ie. Relational Calculus is not equivalent to general-purpose programming languages. It is a specialised calculus intended for the Relational Database Model. Thus while two languages may be relationally complete, each may have features over and above that required for relational completeness (but these need not concern us here).
Relational Calculus, as we shall see later, provides constructs (well-formed expressions) to specify relations. These constructs are very much in a declarative style. Relational Algebra, on the other hand, also provides constructs for relational database manipulations but in a more procedural style. Moreover, it has also been established that Relational Algebra is equivalent to Relational Calculus, in that every expression in one has an equivalent expression in the other. Thus relational completeness of a database language can also be established by showing that it can define any relation expressible in Relational Algebra.
Why then should we bother with different languages and styles of expression if they are all in some sense equivalent? The answer is that besides equivalence (relational or computational), there are other valid issues that different language designs try to address including the level of abstraction, precision, comprehensibility, economy of expression, ease of writing specifications, efficiency of execution, etc. Declarative constructs, by virtue of their descriptive nature (as opposed to the prescriptive nature of procedural constructs), are closer to natural language and thus easier to write and understand. Designers of declarative languages try to provide constructs that even end-users (with a little training) can use to formulate, for example, ad hoc queries. Declarative constructs, however, execute less efficiently than equivalent procedural ones. Attempts to make them more efficient typically involve first, automatic translation to equivalent procedural form, and second, optimising the resulting expressions according to some predetermined rules of optimisation. In fact, this was the original motivation for the Algebra, ie. providing a set of operations to which expressions of the Calculus could be translated and subsequently optimised for execution. But the efficency of even this approach cannot match that of carefully hand-coded procedural specifications. Thus for periodical and frequently executed manipulations, it is more efficient to use algebraic forms of database languages.
Because of the fundamental nature and role of the Relational Algebra and Calculus in relational databases, we will look at them in depth in the ensuing chapters. This will provide readers with the basic knowledge of database manipulations possible in the model. We begin in this chapter with Relational Algebra.
Overview of Relational Algebra Relational Algebra comprises a set of basic operations. An operation is the application of an operator to one or more source (or input) relations to produce a new relation as a result. This is illustrated in Figure 5-1 below. More abstractly, we can think of such an operation as a function that maps arguments from specified domains to a result in a specified range. In this case, the domain and range happen to be the same, ie. relations.
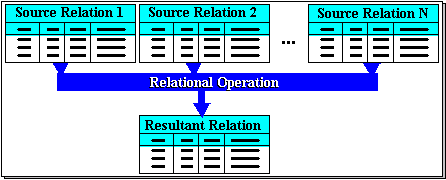
A relational algebraic operation
This is no different in principle to, say, operations in arithmetic. For example, the ‘add’ operation in arithmetic takes two numbers and produces a number as a result. In arithmetic, we are used to writing expressions to denote operations and their results. Thus, the ‘add’ operation is usually written using the ‘+’ symbol (the operator) placed between its two aguments, eg. 145 + 168. Moreover, because an expression denotes the result of the operation (which is of the same type as its input arguments), it itself can be written as an argument in another operation, allowing us to construct complex expressions to denote one result, eg. 145 + 168 - 20 x 3.
Complex expressions that combine different operations are evaluated by a sequence of reductions. The sequence, in the case of arithmetic expressions, is determined by the familiar precedence of operators. Thus, the expression 145 + 168 - 20 x 3 would be reduced as follows:
145 + 168 - 20 x 3 = 145 + 168 - 60 = 313 - 60 = 253
This default precedence can be overridden with the explicit use of parenthesis. Thus,
(145 + (168 - 20)) x 3 = (145 + 148) x 3 = 393 x 3 = 1179
All these would of course be elementary to the reader! The point though is that the basic operations of relational algebra are defined to allow manipulations of relations in much the same way that arithmetic operations manipulate numbers above. With appropriately defined symbols to denote operators and syntax to denote the application of operators to arguments (relations), relational expressions combining multiple operations can be constructed to denote a resultant relation. And as with arithmetic expressions, (algebraic) relational expressions are evaluated by reduction in some specified (default or explicit) order. Thus the earlier statement that relational algebra is basically procedural in nature, ie. operations and their sequencing are explicitly specified to achieve a particular transformation of input(s) to output.
The analogy with arithmetic above has been useful to highlight the basic nature of relational algebra. However, the algebra’s basic operations are much more complex than those of arithmetic. They are in fact much more related to operations on sets (viz. intersection, union, difference, etc). This is not surprising as relations are after all special kinds of sets.
As mentioned above, a relational operation maps relations to a relation. As a relation is completely defined by its intension and extension, the complete definition of a relational operation must specify both the schema of the resultant relation and the rules for generating its tuples from the input relation(s). In the following, we will do just that. Moreover, in the interest of clarity as well as precision of presentation, we will define each basic operation both informally and formally.
While notations used to denote the basic operators and operations may differ in the literature, there is no disagreement in their basic logical definitions. It will be necessary for us to use some concrete notation in what follows and, rather than introducing yet more notations, we have chosen in fact to use Codd’s original notation.
Selection
Selection is used to extract tuples from a relation. A tuple from the source relation is selected (or not) based on whether it satisfies a specified predicate (condition). A predicate is a truth-valued expression involving tuple component values and their relationships. All tuples satisfying the predicate are then collected into the resultant relation. The general effect is illustrated in Figure 5-2.
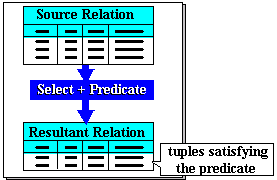
The select operation
For example, consider the ‘Customer’ source relation below:
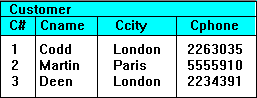
The result of a selection operation applied to it with the condition that the attribute ‘Ccity’ must have the value "London" will be:

because these are the only tuples that satisfy the stated condition. Procedurally, you may think of the operation as examining each tuple of the source relation in turn (say from top to bottom), checking to see if it met the specified condition before turning attention to the next tuple. If a tuple satisfies the condition, it is included in the resultant relation, otherwise it is ignored.
We shall use the following syntax to express a selection operation:
select
where
giving
The
where

br>
<