Theoretical Paper
- Computer Organization
- Data Structure
- Digital Electronics
- Object Oriented Programming
- Discrete Mathematics
- Graph Theory
- Operating Systems
- Software Engineering
- Computer Graphics
- Database Management System
- Operation Research
- Computer Networking
- Image Processing
- Internet Technologies
- Micro Processor
- E-Commerce & ERP
Practical Paper
Industrial Training

Functional Dependencies
The concept of functional dependency (also known as normalization was introduced by professor Codd in 1970 when he defined the first three normal forms (first, second and third normal forms). Normalization is used to avoid or eliminate the three types of anomalies (insertion, deletion and update anomalies) which a database may suffer from. These concepts will be clarified soon, but first let us define the first three normal forms.
First Normal Form: A relation is in first normal form if all its attributes are simple. In other words, none of the attributes of the relation is a relation. Notice that relation means 2-diemenatioanl table.
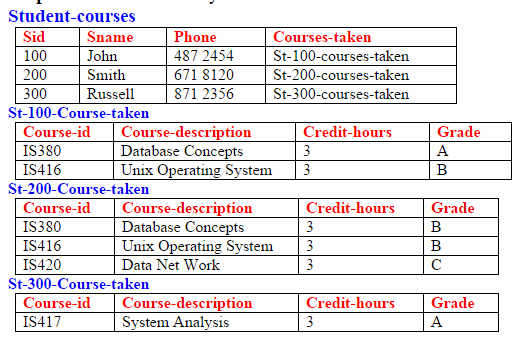
Example -1. Assume the following relation
Student-courses (Sid:pk, Sname, Phone, Courses-taken)
Where attribute Sid is the primary key, Sname is student name, Phone is student's phone number and Courses-taken is a table contains course-id, course-description, credit hours and grade for each course taken by the student. More precise definition of table Course-taken is :
Course-taken (Course-id:pk, Course-description, Credit-hours, Grade)
According to the definition of first normal form relation Student-courses is not in first normal form because one of its attribute Courses-taken is itself a table and is not a simple attribute. To clarify it more assume the above tables contain the data as shown below:
Definition of the three types of anomalies:
Insertion anomaly means that that some data can not be inserted in the database. For example we can not add a new course to the database of example-1,unless we insert a student who has taken that course.
Update anomaly means we have data redundancy in the database and to make any modification we have to change all copies of the redundant data or else the database will contain incorrect data. For example in our database we have the Course description "Database Concepts" for IS380 appears in both St-100-Course-taken and St-200-Course-taken tables. To change its description to "New Database Concepts" we have to change it in all places. Indeed one of the purposes of normalization is to eliminate data redundancy in the database.
Deletion anomaly means deleting some data cause other information to be lost. For example if student Russell is deleted from St-100-Course-taken table we also lose the information that we had a course call IS417 with description System Analysis.
Thus Student-courses table suffers from all the three anomalies.
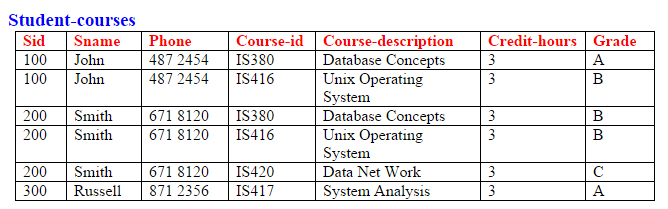
To convert the above structure to first normal form relations, all non-simple attributes must be removed or converted to simple attribute. To do that a new relation is created by combining each row of Student-courses with all rows of its corresponding course table that was taken by that specific student. Following is Student-courses table in first normal form.
Student-courses ( Sid:pk1, Sname, Phone, Course-id:pk2,
Course-description, Credit-hours, Grade)
Notice that the primary key of this table is a composite key made up of two parts; Sid and Course-id. Note that pk1 following an attribute indicates that the attribute is the first part of the primary key and pk2 indicates that the attribute is the second part of the primary key.
Definition of the three types of anomalies:
Insertion anomaly means that that some data can not be inserted in the database. For example we can not add a new course to the database of example-1,unless we insert a student who has taken that course.
Update anomaly means we have data redundancy in the database and to make any modification we have to change all copies of the redundant data or else the database will contain incorrect data. For example in our database we have the Course description "Database Concepts" for IS380 appears in both St-100-Course-taken and St-200-Course-taken tables. To change its description to "New Database Concepts" we have to change it in all places. Indeed one of the purposes of normalization is to eliminate data redundancy in the database.
Deletion anomaly means deleting some data cause other information to be lost. For example if student Russell is deleted from St-100-Course-taken table we also lose the information that we had a course call IS417 with description System Analysis.
Thus Student-courses table suffers from all the three anomalies.
To convert the above structure to first normal form relations, all non-simple attributes must be removed or converted to simple attribute. To do that a new relation is created by combining each row of Student-courses with all rows of its corresponding course table that was taken by that specific student. Following is Student-courses table in first normal form.
Student-courses ( Sid:pk1, Sname, Phone, Course-id:pk2,
Course-description, Credit-hours, Grade)
Notice that the primary key of this table is a composite key made up of two parts; Sid and Course-id. Note that pk1 following an attribute indicates that the attribute is the first part of the primary key and pk2 indicates that the attribute is the second part of the primary key.
Examination of the above Student-courses relation reveals that Sid does not uniquely identify a row (tuple) in the relation hence cannot be the primary key. For the same reason Course-id cannot be the primary key. However the combination of Sid and Course-id uniquely identifies a row in Student-courses, Therefore (Sid, Course-id) is the primary key of the above relation.
The primary key determines every attribute. For example if you know both Sid and Course-id for any student you will be able to retrieve Sname, Phone, Course-description, Credit-hours and Grade, because these attributes are dependent on the primary key. Figure 1 below is the graphical representation of the functional dependency between the primary key and attributes of the above relation.
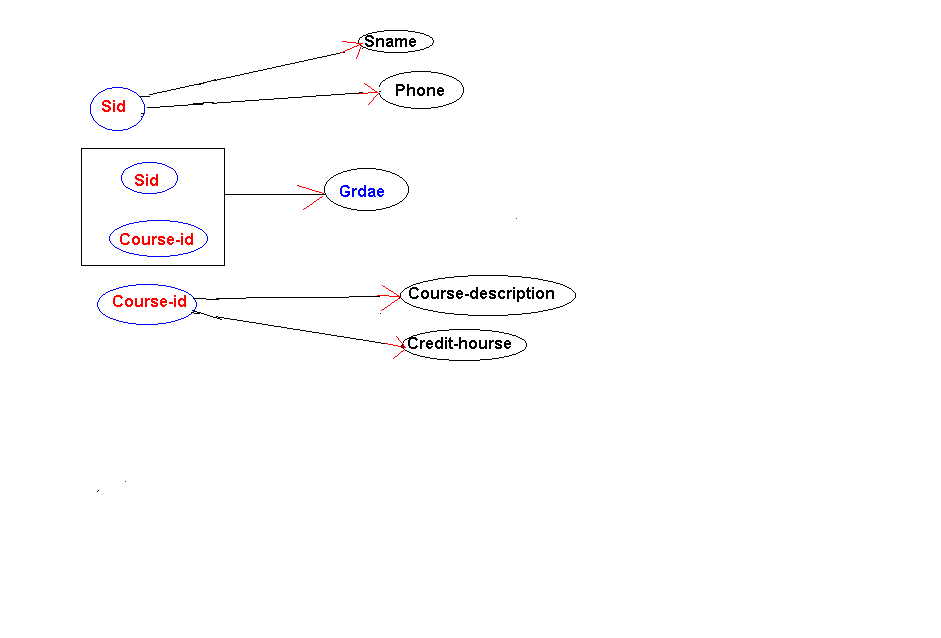
Note that the attribute to the right of the arrow is functionally dependent on the attribute in the left of the arrow. Thus the combination (Sid, Course-id) is the determinant (that determines other attributes) and attributes Sname, Phone, Course-description, Credit-hours and Grade are dependent attributes.
Formally speaking a determinant is an attribute or a group of attributes determine the value of other attributes. In addition to the (Sid, Course-id) there are two other determinants in the above Student-courses relation. These are; Sid and Course-id attributes. Note that Sid alone determines both Sname and Phone, and attribute Course-id alone determines both Credit-hours and Course_description attributes.
Attribute Grade is fully functionally dependent on the primary key (Sid, Course-id) because both parts of the primary keys are needed to determine Grade. On the other hand both Sname, and Phone attributes are not fully functionally dependent on the primary key, because only a part of the primary key namely Sid is needed to determine both Sname and Phone. Also attributes Credit-hours and Course-Description are not fully functionally dependent on the primary key because only Course-id is needed to determine their values.
The new relation Student-courses still suffers from all three anomalies for the following reasons:
1. The relation contains redundant data (Note Database_Concepts as the course
description for IS380 appears in more than one place).
2. The relation contains information about two entities Student and course.
Following is the detail description of the anomalies that relation Student-courses suffers from.
1. Insertion anomaly: We cannot add a new course such as IS247 with course description programming techniques to the database unless we add a student who to take the course.
2. Update anomaly: If we change the course description for IS380 from Database Concepts to New_Database_Concepts we have to make changes in more than one place or else the database will be inconsistent. In other words in some places the course description will be New_Database_Concepts and in any place were we forgot to make the changes the description still will be Database_Concepts.
3. Deletion anomaly: If student Russell is deleted from the database we also loose information that we had on course IS417 with description System_Analysis.
The above discussion indicates that having a single table Student-courses for our database causing problems (anomalies). Therefore we break the table to smaller table to get a higher normal form relation. Before doing that let us define the second normal form.
Second normal relation: A first normal form relation is in second normal form if all its non-primary attributes are fully functionally dependent on the primary key.
Note that primary attributes are those attributes, which are parts of the primary key, and non-primary attributes do not participate in the primary key. In Student-courses relation both Sid and Course-id are primary attributes because they are components of the primary key. However attributes Sname, Phone, Course-description, Credit-hours and Grade all are non primary attributes because non of them is a component of the primary key.
To convert Student-courses to second normal relations we have to make all non-primary attributes to be fully functionally dependent on the primary key. To do that we need to project (that is we break it down to two or more relations) Student-courses table into two or more tables. However projections may cause problems. To avoid such problems it is important to keep attributes, which are dependent on each other in the same table, when a relation is projected to smaller relations. Following this principle and examination of Figure-1 indicate that we should divide Student-courses relation into following three relations:
PROJECT Student-courses ON (Sid, Sname, Phone) creates a table call it Student. The relation Student will be Student (Sid:pk, Sname, Phone) and
PROJECT Student-courses ON (Sid, Course-id, Grade) creates a table call it Student-grade. The relation Student-grade will be
Student-grade (Sid:pk1:fk:Student, Course-id::pk2:fk:Courses, Grade) and
Projects Student-courses ON (Course-id, Course-Description, Credit-hours) create a table call it Courses. Following are these three relations and their contents:
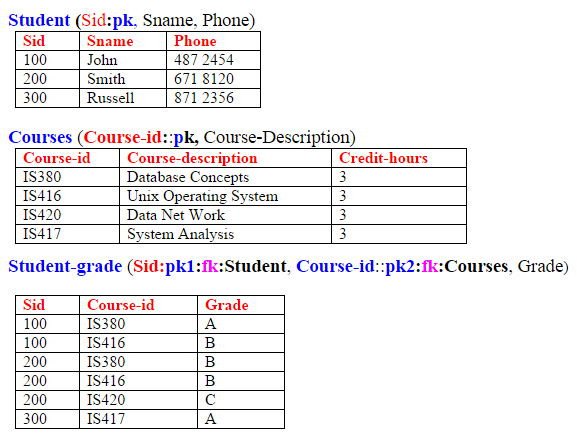
All these three relations are in second normal form. Examination of these relations shows that we have eliminated the redundancy in the database. Now relation Student contains information only related to the entity student, relation Courses contains information related to entity Courses only, and the relation Student-grade contains information related to the relationship between these two entity.
Further these three sets are free from all anomalies. Let us clarify this in more detail.
Insertion anomaly: Now a new Course with course-id IS247 and Course-description can be inserted to the table Course. Equally we can add any new students to the database by adding their id, name and phone to Student table. Therefore our database, which made up of these three tables does not suffer from insertion anomaly.
Update anomaly: Since redundancy of the data was eliminated no update anomaly can occur. To change the course-description for IS380 only one change is needed in table Courses.
Deletion anomaly: the deletion of student Russell from the database is achieved by deleting Russell's records from both Student and Student-grade relations and this does not have any side effect because the course IS417 untouched in the table Courses.
Third Normal Form: A second normal form relation is in third normal form if all non-primary attributes (that is attributes that are not parts of the primary key or of any candidate key) have non-transitivity dependency on the primary key.
Assume the relation:
STUDENT (Sid: pk, Activity, fee)
Further Activity ------------> fee that is the Activity determine the fee
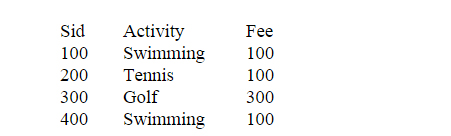
Table STUDENT is in first normal form because all its attributes are simple. Also STUDENT is in second normal form because all its non-primary attributes are fully functionally dependent on the primary key (Sid). Notice that a first normal relation with non-composite (that is simple) primary key automatically will be in second normal form because all its non-primary attributes will be fully functionally dependent on the primary key.
Table STUDENT suffers from all 3 anomalies; a new student can not be added to the database unless he/she takes an activity and no activity can be inserted into the database unless we get a student to take that activity. There is redundancy in the table (see Swimming), therefore to change the fee for Swimming we must make changes in more than one place and that will cause update anomaly problem. If student 300 is deleted from the table we also loose the fact that we had Golf activity with its fee to be 300. To overcome these anomalies STUDENT table should be converted to smaller tables. Consider the following three projection of the STUDENT relation:
PROJECT STUDENT on [Sid, Activity] and we get a relation name it
STUD-AVT (Sid:pk, Activity) with the following data :

The question is which pairs of these projections should we choose? The answer to that is to choose the pair STUD-AVT and AVT-Fee because the join of these two projections produces the original STUDENT table. Such projections are called non-loss projections. Therefore the join of STUD-AVT and AVT-Fee on the common attribute Activity recreate the original STUDENT table. On the other hand as shown below the join of projections Sid-Fee and AVT-Fee on their common attribute Sid generates erroneous data that were not in the original STUDENT table and such projections are called loss projections. Following is the join of projections Sid-Fee and AVT-Fee on their common attribute Sid
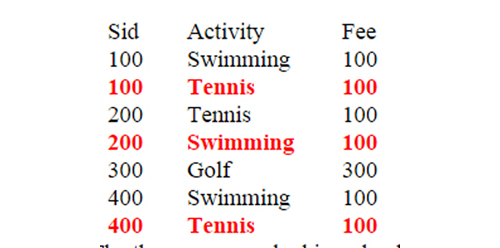
The three rows marked in red color were not in the original STUDENT table. Thus we have an erroneous data in the database.
Both projections STUD-AVT and AVT-Fee are in third normal form and they do not suffer from any anomalies.
Boyce Codd normal (BOC): A relation is in BOC form if every determinant is a candidate key. This is an improved form of third normal form.
Fourth Normal Form: A Boyce Codd normal form relation is in fourth normal form if there is no multi value dependency in the relation or there are multi value dependency but the attributes, which are multi value dependent on a specific attribute, are dependent between themselves. This is best discussed through mathematical notation. Assume the following relation
R(a:pk1, b:pk2, c:pk3)
Recall that a relation is in BOC normal form if all its determinant are candidate keys, in other words each determinant can be used as a primary key. Because relation R has only one determinant (a, b, c),, which is the composite primary, key and since the primary is a candidate key therefore R is in BOC normal form.
Now R may or may not be in fourth normal form.
1. If R contains no multi value dependency then R will be in Fourth normal form.
2. Assume R has the following two-multi value dependencies:
a ------->> b and a ---------->> c
In this case R will be in the fourth normal form if b and c dependent on each other. However if b and c are independent of each other then R is not in fourth normal form and the relation has to be projected to following two non-loss projections. These non-loss projections will be in fourth normal form.
Example:
Case 1:
Assume the following relation:
Employee (Eid:pk1, Language:pk2, Skill:pk3)
No multi value dependency, therefore R is in fourth normal form.
case 2:
Assume the following relation with multi-value dependency:
Employee (Eid:pk1, Languages:pk2, Skills:pk3)
Eid ---->> Languages Eid ------>> Skills
Languages and Skills are dependent.
This says an employee speak several languages and has several skills. However for each skill a specific language is used when that skill is practiced.
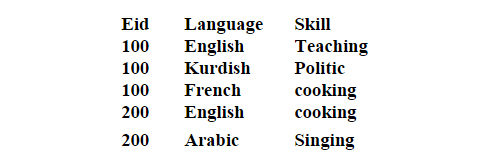
Thus employee 100 when he/she teaches speaks English but when he cooks speaks French. This relation is in fourth normal form and does not suffer from any anomalies.
case 3:
Assume the following relation with multi-value dependency:
Employee (Eid:pk1, Languages:pk2, Skills:pk3)
Eid ---->> Languages Eid ------>> Skills
Languages and Skills are independent

This relation is not in fourth normal form and suffers from all three types of anomalies. Insertion anomaly: To insert row (200 English Cooking) we have to insert two extra rows (200 Arabic cooking), and (200 English Singing) otherwise the database will be inconsistent. Note the table will be as follow:

Deletion anomaly: If employee 100 discontinue politic skill we have to delete two rows
(100 Kurdish Politic), and (100 English Politic) otherwise the database will be inconsistent.
Update anomaly: If employee 200 changes his skill from singing to dancing we have to make changes in more than one place
The relation is projected to the following two non-loss projections which are in forth normal form
