Theoretical Paper
- Computer Organization
- Data Structure
- Digital Electronics
- Object Oriented Programming
- Discrete Mathematics
- Graph Theory
- Operating Systems
- Software Engineering
- Computer Graphics
- Database Management System
- Operation Research
- Computer Networking
- Image Processing
- Internet Technologies
- Micro Processor
- E-Commerce & ERP
Practical Paper
Industrial Training

Data Sublanguage QBE
Introduction
Data Query Languages were developed in the early seventies when the man-machine interface was, by today’s standards, limited and rudimentary. In particular, interaction with the computer was through the processing of batched jobs, where jobs (computation requests such as "run this program on that data", "evaluate this database query", etc) were prepared off-line on some computer readable media (eg. punch cards), gathered into a ‘batch’ and then submitted for processing. No interaction takes place between the user and computer while the jobs were processed. End results were instead typically printed for the user to inspect (again off-line) and to determine the next course of action. The batch cycle continued until the user had obtained the desired results.
This was pretty much the way database queries were handled (see Figure 11-1). As data coding devices were exclusively textual in nature and as processing is non- interactive, queries must be defined textually and each query must be self-contained (ie. has all the components required to complete the evaluation). The design of early languages were influenced by, and in fact had to comply with, these constraints to be usable. Thus, for example, the SQL query:
Select P# from Transaction
where C# IN ( Select C# from Customer
where Ccity = London )
could be easily encoded as a job for batched submission. Needless to say, the turnaround time in such circumstances were high, taking hours or even days before a user sees the results of submitted queries. Many hours are typically spent off-line for a job that would take seconds to evaluate, and it is even worse if you made an error in your submission!
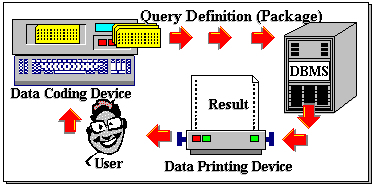
Over the past 20 years, however, man-machine interfaces or human-computer interaction (HCI) has progressed in leaps and bounds. Today, graphical user interfaces (GUI) are taken for granted and the batched mode of processing is largely a past relic replaced by highly interactive computing. Nevertheless, many database query languages today still retain the old ‘batch’ characteristics and do not exploit features of interactive interfaces. This is perhaps not surprising as, first, a large body of techniques for processing textual languages had grown over the years (eg. compiling and optimisation) and, second, they were well suited for embedding in more general purpose programming languages. The latter especially provides great flexibility and power in database manipulation. Also, as the paradigm shifted to interactive computing, its application to database queries was not immediately obvious. But end- user computing is, in any case, increasing and many tasks that previously required the skills of expert programmers are now being performed by end-users through visual, interactive interfaces.
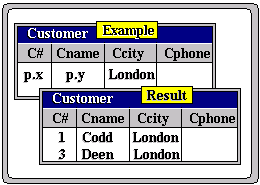
Query-By-Example (QBE) is the first interactive database query language to exploit such modes of HCI. In QBE, a query is a construction on an interactive terminal involving two-dimensional ‘drawings’ of one or more relations, visualised in tabular form, which are filled in selected columns with ‘examples’ of data items to be retrieved (thus the phrase query-by-example). The system answers the query by fetching data items based on the given example and drawing the result on the same screen
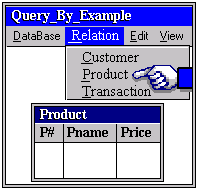
Typically, the ‘drawing’ of relations are aided by interactive commands made available through pull-down menus (see Figure 11-3). The menu selection is constrained to relations available in the schema and thus eliminates errors in specifying relation structures or attribute names as can occur in text-based languages like SQL. The interface provided is in effect a structured editor for a graphical language.
For the remainder of this chapter, we will focus exclusively on the principal features of QBE. In contrast to SQL, QBE is based on relational calculus with domain variables (see 8.2). To close this introduction, we should mention that QBE was developed by M.M. Zloof at the IBM Yorktown Heights Laboratory.
Variables and Constants
In filling out a selected table with an example, the simplest item that can be entered under a column is a free variable or a constant. A free variable in QBE must be an underlined name (identifier) while a constant can be a number, string or other constructions denoting a single data value. A query containing such combinations of free variables and constants is a request for a set of values instantiating the specified variables while matching the constants under the specified columns.
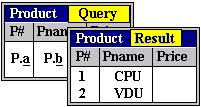
As an example, look at Figure 11-4. Two variables are introduced in the query: a and b. By placing a variable under a column, we are in effect assigning that variable to range over the domain of that column. Thus, the variable a ranges over the domain P# while b ranges over Pname.
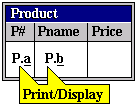
The reader would have also noted that the variables are prefixed by "P.". In QBE, this is required if the instantiation found for the specified variable is to be displayed, ie. the prefix "P." may be thought of as a command to print. We will say more about prefix commands like this later. Suffice it for now to say that if neither variable in Figure 11-4 was preceded by "P." then the result table would display nothing!
The query in Figure 11-4 is in fact equivalent to the following construction of relational calculus with domain variables:
a ® P#; b ® Pname;
(a, b): ( Product (a, b) )
Assuming the usual Product relation extension as in previous chapters, the result of the query is shown in
Let us consider another simple example and walk through the basic interactions necessary to formulate the query and get the desired results. Suppose we wanted the names and cities of all customers. The basic interactions are summarised in
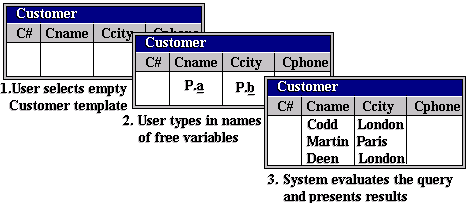
1. The user first uses a pull-down menu as in Figure 11-3 to select the appropriate relation(s) containing the desired items. For this query, the Customer relation would seem the most appropriate and selecting it would result in an empty template being displayed.
2. Inspecting the template, the user can ascertain that the desired data items are indeed in the selected template (viz. The Cname and Ccity columns). Next, the user invents variable identifiers (a and b) and types each under the appropriate column. This is all that is required for this query.
3. Finally, the example is evaluated by the system and the results displayed on the screen.
This is the basic interaction even for more complex queries - select relation templates, fill in example items, then let the system evaluate and display the results. Of course, with more complex queries, more than one relation may be used and constructing the example will usually involve more than just free variables, as we shall see in due course.