Theoretical Paper
- Computer Organization
- Data Structure
- Digital Electronics
- Object Oriented Programming
- Discrete Mathematics
- Graph Theory
- Operating Systems
- Software Engineering
- Computer Graphics
- Database Management System
- Operation Research
- Computer Networking
- Image Processing
- Internet Technologies
- Micro Processor
- E-Commerce & ERP
Practical Paper
Industrial Training

Introduction to Databases
Introduction
We live in an information age. By this we mean that, first, we accept the universal fact that information is required in practically all aspects of human enterprise. The term ‘enterprise’ is used broadly here to mean any organisation of activities to achieve a stated purpose, including socio-economic activities. Second, we recognise further the importance of efficiently providing timely relevant information to an enterprise and of the importance of the proper use of technology to achieve that. Finally, we recognise that the unparallelled development in the technology to handle information has and will continue to change the way we work and live, ie. not only does the technology support existing enterprises but it changes them and makes possible new enterprises that would not have otherwise been viable.
The impact is perhaps most visible in business enterprises where there are strong elements of competition. This is especially so as businesses become more globalised. The ability to coordinate activities, for example, across national borders and time zones clearly depends on the timeliness and quality of information made available. More important perhaps, strategic decisions made by top management in response to perceived opportunities or threats will decide the future viability of an enterprise, one way or the other. In other words, in order to manage a business (or any) enterprise, future development must be properly estimated. Information is a vital ingredient in this regard.
Information must therefore be collected and analysed in order to make decisions. It is here that the proper use of technology will prove to be crucial to an enterprise. Up-to- date management techniques should include computers, since they are very powerful tools for processing large quantities of information. Collecting and analysing information using computers is facilitated by current Database Technology, a relatively mature technology which is the subject of this book.
Information Model
Information stored in computer memory is called data. In current computer systems, such data can (persistently) reside on a number of memory devices, most common of which are floppy disks, CD-ROMs, and hard disks.
Data that we store and manipulate using computers are meaningful only to the extent that they are associated with some real world object in a given context. Take, for example, the number ‘23’. This is a piece of data, but by itself a meaningless quantity. If it was associated with, say, a person and interpreted to denote that person’s age (in years), then it begins to be more meaningful. Or, if it was associated with, say, an organisation that sells electronic goods and interpreted to mean the number of television sets sold in a given month, then again it becomes more meaningful. Notice that in both preceding examples, other pieces of data had to be brought into context - a person, a person’s age, a shop, television sets, a given month, etc.
If the data is a collection of related facts about some enterprise (eg. a business, an organisation, an activity, etc), then it is called a database. The data stored need not include every conceivable piece of fact about that enterprise. Usually, only facts relevant to some area of an enterprise are captured and organised, typically to provide information to support decision making at various levels (operational, management, etc). Such a constrained area of focus is also often referred to as the problem domain or domain of interest, and is typical of databases. In this sense, a database is an information model of some (real-world) problem domain.
Entities
Information models operate on so-called entities and entity relationships. In this section we will clarify what an entity is. Entity relationships are described in 1.2.2. An entity is a particular object in the problem domain. For example, we can extend the electronics organisation above to identify three distinct entities: products, customers and sales representatives (see Figure 1-1). They are distinct from one another in the sense that each has characteristic properties or attributes that distinguish it from the others. Thus a product has properties such as type, function, dimensions, weight, brand name, cost and price; a customer has properties such as name, city of residence, age, credit rating, etc.; and a sales representative has properties such as name, address, sales region, basic salary, etc. Each entity is thus modelled in the database as a collection of data items corresponding to its relevant attributes. (Note that we distinguish between entities even if in the real world they are from the same class of objects. For example, a customer and a sales representative are both people, but a customer is a person who purchases goods while a sales representative is one who sells goods. The different ‘roles’ played distinguishes each from the other) Note also the point made earlier that an information model captures only what is relevant in the given problem domain. Certainly, there are other entities in the organisation - regional offices, warehouses, store keepers, distributors, etc - but these may be irrelevant in the context of, say, analysing sales transactions and are thus omitted from the information model. Even at the level of entity attributes, not all conceivable properties need be captured as data items. A customer’s height, weight, hair colour, hobby, formal qualification, favourite foods, etc, are probably irrelevant and can thus omitted from the model.
Strictly speaking, the objects we referred to above as entities are perhaps more accurately called entity classes because they each denote a set of objects (individual entities), each of which exhibits the properties/attributes described for the class. Thus the entity class ‘customer’ is made up of individual entities, each of which has attributes ‘name’, ‘city of residence’, ‘age’, etc. Every individual entity will then have these attributes but one individual will differ from another in the values (data items) associated with attributes. For example, one customer entity might have the value ‘Smith’ as its ‘name’ attribute, while another might have the value ‘Jones’.

Problem domain entities and their attributes
Notice now that in our information model an attribute is really a pair: an attribute description or name (such as ‘age’) and an attribute value (such as ‘56’), or simply, an ‘attribute–value’ pair. An individual entity is completely modelled only when all its attribute descriptions have been associated with appropriate attribute values. The collection of attribute–value pairs that model a particular individual entity is termed a data object. Figure 1-2 illustrates three data objects in the database, each being a complete model of an individual from its corresponding entity class.

Data objects model particular entities in the real world
Entity Relationships
An entity by itself is often not as interesting or as informative as when it relates in some way to some other entity or entities. A particular product, say a CD-ROM drive, itself only tells us about its intrinsic properties as recorded in its associated data object. A database, however, models more than individual entities in the problem domain. It also models relationships between entities.
In the real world, entities do not stand alone. A CD-ROM drive is supplied by a supplier, is stored in a warehouse, is bought by a customer, is sold by a sales representative, is serviced by a technician, etc. Each of these is an example of a relationship, a logical association between two or more entities.
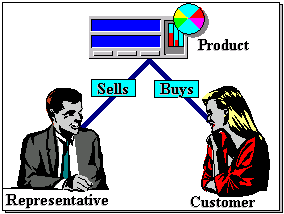
Relationships between entities
Figure 1-3 illustrates such relationships by using links labelled with the type of association between entities. In the figure, a representative sells a product and a customer buys a product. Taken together, these links and the entities they link model a sales transaction: a particular sales transaction will have a product data object related (through the ‘sells’ relation) to a representative data object and (through the ‘buys’ relation) to a customer data object.
Like entity attributes, there are many more relationships than are typically captured in an information model. The choices are of course based on judgements of relevance given a problem domain. Once choices are made and the database populated with particular data objects and relationships, it can then be used to analyse the data to support decision making. In the simple example developed so far, there are already many types of analysis that can be carried out, eg. the distribution of sales of a particular product type by sales region, the performance of sales representatives (measured perhaps by total value of sales in some time interval), product preferences by customer age groups, etc.
Database Management
The real world is dynamic. As an organisation goes about its business, entities are created, modified or destroyed. Similarly with entity relationships. This is easy to see even for the simple problem domain above, eg. when a sales is made, the product sold is then logically linked to the customer that bought it and to the representative that sold it. Many sales transactions could take place each day and thus many new logical links created between many individual entities. New entities can also be introduced, eg. a new customer arrives on the scene, a new product is offered, or a new salesperson is hired. Likewise, some entities may no longer be of concern to the organisation, eg. a product is discontinued, a salesperson quits or is fired, etc (these entities may still exist in the real world but have become irrelevant for the problem domain). Clearly, an information model must also change to reflect the changes in the problem domain that it models.
If the problem domain is small, involving only a few entities and relationship, and the dynamic changes are relatively few or infrequent, manual methods may be sufficient to maintain an accurate record of the state of the business. But if hundreds or thousands of entities are involved and the business is very dynamic, then maintaining accurate records of its state becomes more of a problem. This is when computers with their immense power to handle large amounts of information become crucial to an organisation. Frequently, it is not just a question of efficiency, but of survival, especially in intensely competitive business sectors. The need to use computers to efficiently and effectively store databases and to keep them current has developed over the years special software packages called Database Management Systems (DBMS). A DBMS enables users to create, modify, access and protect their databases
A DBMS is a tool to create and use databases
In other words, a DBMS is a tool to be applied by users to build an accurate and useful information model of their enterprise.
Conceptually, database management is based on the idea of separating a database structure from its contents. Quite simply, a database structure is a collection of static descriptions of entity classes and relationships between them. At this point, it is perhaps simplest to think of an entity class description as a collection of attribute labels. Entity contents can then be thought of as the values that get associated with attribute labels, creating data objects. In other words, the distinction between structure and content is little more than the distinction made earlier between attribute label and attribute value.
Separation of structure from content
Relationship descriptions likewise are simply labelled links between entity descriptions. They specify possible links between data objects, ie. two data objects can be linked only if the database structure describes a link between their respective entity classes. Figure 1-5 illustrates this separation of structure from content. The database structure is also called a schema (or meta-structure - because it describes the structure of data objects). It predefines all possible states of a database, in the sense that no state of the database can contain a data object that is not the result of instantiating an entity schema, and likewise no state can contain a link between two data objects unless such a link was defined in the schema.