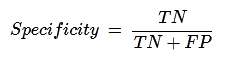Theoretical Paper
- Computer Organization
- Data Structure
- Digital Electronics
- Object Oriented Programming
- Discrete Mathematics
- Graph Theory
- Operating Systems
- Software Engineering
- Computer Graphics
- Database Management System
- Operation Research
- Computer Networking
- Image Processing
- Internet Technologies
- Micro Processor
- E-Commerce & ERP
Practical Paper
Industrial Training

Machine Learning - Performance Metrics
There are various metrics which we can use to evaluate the performance of ML algorithms, classification as well as regression algorithms. We must carefully choose the metrics for evaluating ML performance because −
- How the performance of ML algorithms is measured and compared will be dependent entirely on the metric you choose.
- How you weight the importance of various characteristics in the result will be influenced completely by the metric you choose.
Performance Metrics for Classification Problems
We have discussed classification and its algorithms in the previous chapters. Here, we are going to discuss various performance metrics that can be used to evaluate predictions for classification problems.
Confusion Matrix
Explanation of the terms associated with confusion matrix are as follows −
- True Positives (TP) − It is the case when both actual class & predicted class of data point is 1.
- True Negatives (TN) − It is the case when both actual class & predicted class of data point is 0.
- False Positives (FP) − It is the case when actual class of data point is 0 & predicted class of data point is 1.
- False Negatives (FN) − It is the case when actual class of data point is 1 & predicted class of data point is 0.
We can use confusion_matrix function of sklearn.metrics to compute Confusion Matrix of our classification model.
Classification Accuracy
It is most common performance metric for classification algorithms. It may be defined as the number of correct predictions made as a ratio of all predictions made. We can easily calculate it by confusion matrix with the help of following formula −
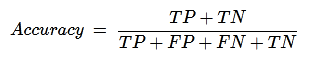
We can use accuracy_score function of sklearn.metrics to compute accuracy of our classification model.
Classification Report
This report consists of the scores of Precisions, Recall, F1 and Support. They are explained as follows −
Precision
Precision, used in document retrievals, may be defined as the number of correct documents returned by our ML model. We can easily calculate it by confusion matrix with the help of following formula −
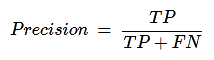
Recall or Sensitivity
Recall may be defined as the number of positives returned by our ML model. We can easily calculate it by confusion matrix with the help of following formula.
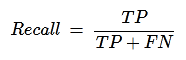
Specificity
Specificity, in contrast to recall, may be defined as the number of negatives returned by our ML model. We can easily calculate it by confusion matrix with the help of following formula −