Theoretical Paper
- Computer Organization
- Data Structure
- Digital Electronics
- Object Oriented Programming
- Discrete Mathematics
- Graph Theory
- Operating Systems
- Software Engineering
- Computer Graphics
- Database Management System
- Operation Research
- Computer Networking
- Image Processing
- Internet Technologies
- Micro Processor
- E-Commerce & ERP
Practical Paper
Industrial Training

Probability Distributions - Concepts
The term "statistical experiment" is used to describe any process by which several chance observations are obtained.
All possible outcomes of an experiment comprise a set that is called the sample space. We are interested in some numerical description of the outcome.
For example, when we toss a coin 3 times, and we are interested in the number of heads that fall, then a numerical value of 0,1,2,3 will be assigned to each sample point.
The numbers 0, 1, 2, and 3 are random quantities determined by the outcome of an experiment.
They may be thought of as the values assumed by some random variable x, which in this case represents the number of heads when a coin is tossed 3 times.
So we could write x1 = 0, x2 = 1, x3 = 2 and x4 = 3.
Definitions
A random variable is a variable whose value is determined by the outcome of a random experiment.
A discrete random variable is one whose set of assumed values is countable (arises from counting).
A continuous random variable is one whose set of assumed values is uncountable (arises from measurement.)
We shall use:
A capital X for the random variable and
Lower case x1, x2, x3... for the values of the random variable in an experiment. These xi then represent an event that is a subset of the sample space.
The probabilities of the events are given by: P(x1), P(x2), P(x3), ...
We also use the notation P(X). For example, we may need to find some of the probabilities involved when we throw a die. We would write for the probability of obtaining a "5" when we roll a die as:
1 P(X=5)= -------- 6
Discrete Random Variable
Two balls are drawn at random in succession without replacement from an urn containing 4 red balls and 6 black balls.
Continuous Random Variable
A jar of coffee is picked at random from a filling process in which an automatic machine is filling coffee jars each with 1 kg of coffee. Due to some faults in the automatic process, the weight of a jar could vary from jar to jar in the range 0.9 kg to 1.05 kg, excluding the latter.
Let X denote the weight of a jar of coffee selected. What is the range of X?
Distribution Function
Definitions
1. A discrete probability distribution is a table (or a formula) listing all possible values that a discrete variable can take on, together with the associated probabilities.
2.The function f(x) is called a probability density function for the continuous random variable X where the total area under the curve bounded by the x-axis is equal to 1. i.e.
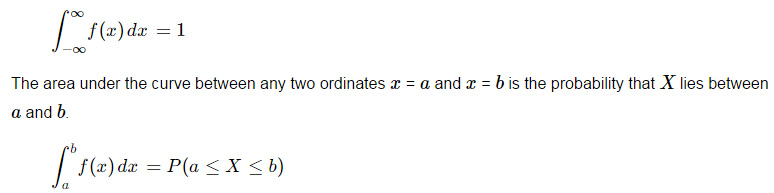
See area under a curve in the integration section for some background on this.
Probabilities As Relative Frequency
If an experiment is performed a sufficient number of times, then in the long run, the relative frequency of an event is called the probability of that event occurring.
Example 3
Refer to the previous example. The weight of a jar of coffee selected is a continuous random variable. The following table gives the weight in kg of 100 jars recently filled by the machine. It lists the observed values of the continuous random variable and their corresponding frequencies.
Find the probabilities for each weight category.
| Weight X | Number of Jars |
|---|---|
| `0.900 - 0.925` | `1` |
| `0.925 - 0.950` | `7` |
| `0.950 - 0.975` | `25` |
| `0.975 - 1.000` | `32` |
| `1.000 - 1.025` | `30` |
| `1.025 - 1.050` | `5` |
| Total | `100` |
Expected Value of a Random Variable
Let X represent a discrete random variable with the probability distribution function P(X). Then the expected value of X denoted by E(X), or μ, is defined as:
E(X) = μ = Σ (xi × P(xi))
To calculate this, we multiply each possible value of the variable by its probability, then add the results.
Σ (xi × P(xi)) = { x1 × P(x1)} + { x2 × P(x2)} + { x3 × P(x3)} + ...
`E(X)` is also called the mean of the probability distribution.
Example 4
In Example 1 above, we had an experiment where we drew `2` balls from an urn containing `4` red and `6` black balls. What is the expected number of red balls?
Example 5
I throw a die and get `$1` if it is showing `1`, and get `$2` if it is showing `2`, and get `$3` if it is showing `3`, etc. What is the amount of money I can expect if I throw it `100` times?
Example 6
The number of persons X, in a Singapore family chosen at random has the following probability distribution:
| X | `1` | `2` | `3` | `4` | `5` | `6` | `7` | `8` |
|---|---|---|---|---|---|---|---|---|
| P(X) | `0.34` | `0.44` | `0.11` | `0.06` | `0.02` | `0.01` | `0.01` | `0.01` |
Find the average family size `E(X)`.
Example 7
In a card game with my friend, I pay a certain amount of money each time I lose. I win `$4` if I draw a jack or a queen and I win `$5` if I draw a king or ace from an ordinary pack of `52` playing cards. If I draw other cards, I lose. What should I pay so that we come out even? (That is, the game is "fair"?)
Variance of a Random Variable
Let X represent a discrete random variable with probability distribution function `P(X)`. The variance of X denoted by `V(X)` or σ2 is defined as:
V(X) = σ2 = Σ[{X − E(X)}2 × P(X) ]
Since μ = E(X), (or the average value), we could also write this as:
V(X) = σ2 = Σ[{X − μ}2 × P(X) ]
Another way of calculating the variance is:
V(X) = σ2 = E(X2) − [E(X)]2
Standard Deviation of the Probability Distribution
`sigma=sqrt(V(X)` is called the standard deviation of the probability distribution. The standard deviation is a number which describes the spread of the distribution. Small standard deviation means small spread, large standard deviation means large spread.
In the following 3 distributions, we have the same mean (μ = 4), but the standard deviation becomes bigger, meaning the spread of scores is greater.
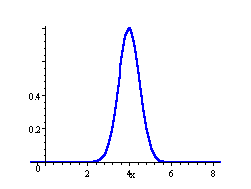
Normal Curve
μ = 4, σ = 0.5
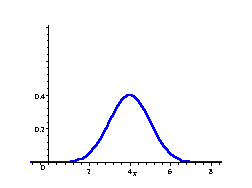
Normal Curve
μ = 4, σ = 1
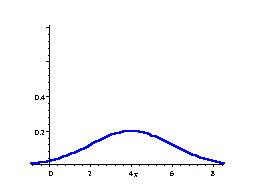
Normal Curve
μ = 4, σ = 2
The area under each curve is `1`.
Example 8
Find `V(X)` for the following probability distribution:
| X | `8` | `12` | `16` | `20` | `24` |
|---|---|---|---|---|---|
| P(X) | `1/8` | `1/6` | `3/8` | `1/4` | `1/12` |